Press "Enter" to skip to content
写在前面
- 昨天, 我们学习了集成学习中的个体与集成; 今天, 我们将继续学习集成学习中的Boosting.
Boosting
- Boosting是一族可将弱学习器提升为强学习器的算法. 这族算法的工作机制类似: 先从初始训练集训练出一个基学习器, 再根据基学习器的表现对训练样本分布进行调整, 使得闲钱基学习器做错的训练样本在后续受到更多关注, 然后基于调整后的样本分布来训练下一个基学习器; 如此重复进行, 直至基学习器数目达到实现指定的值
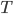 , 最终将这 个基学习器进行加权结合.
, 最终将这 个基学习器进行加权结合.
- Boosting族算法最著名的代表是AdaBoost, 其描述如下图, 其中
 ,
,  是真实函数:
是真实函数:
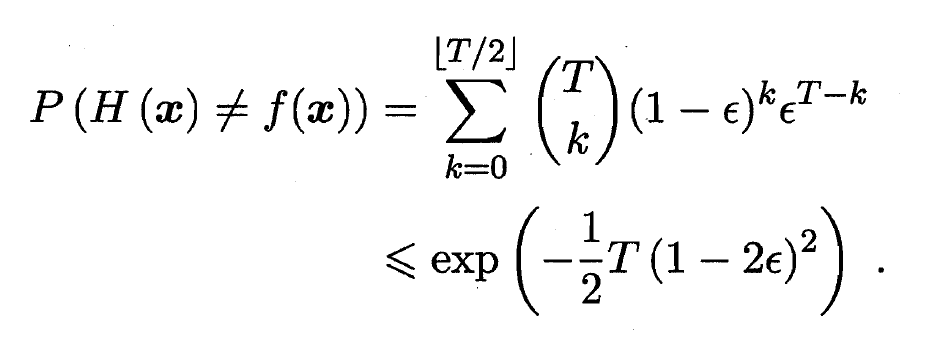
- AdaBoost算法有多种推导方式, 比较容易理解的是基于'加性模型'(Additive Model), 即机器学习器的线性组合:
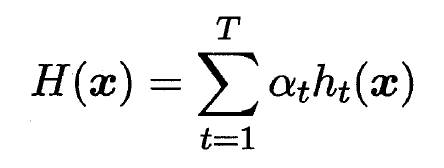
- 来最小化指数损失函数(Exponential Loss Function):
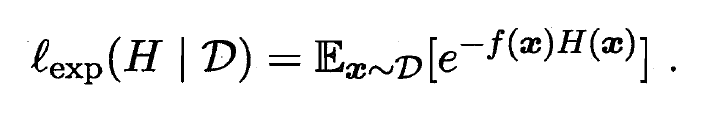

- 若
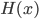 能令指数损失函数最小化, 则考虑对 的偏导:
能令指数损失函数最小化, 则考虑对 的偏导:
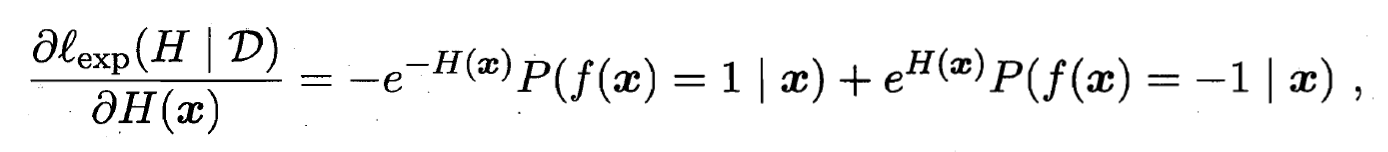
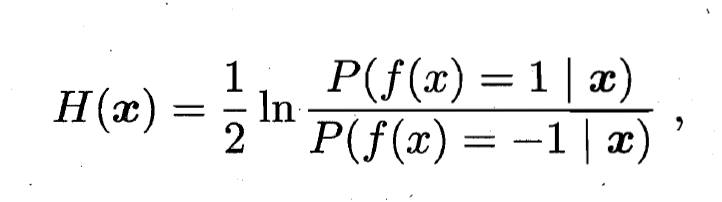
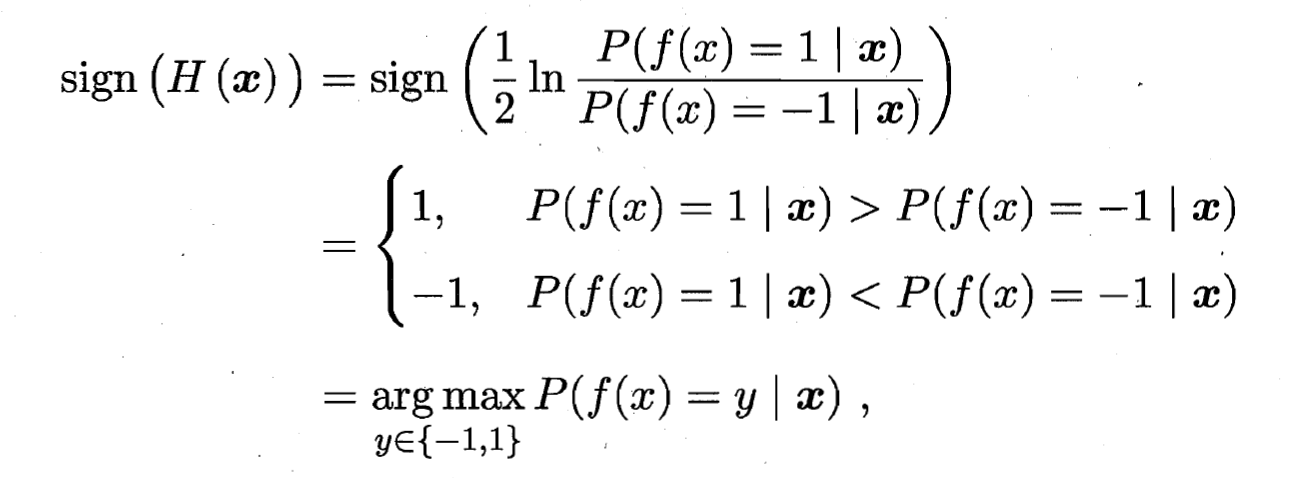
- 这意味着
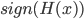 达到了贝叶斯最优错误率. 换言之, 若指数损失函数最小化, 则分类错误率也将最小化; 这说明指数损失函数是分类任务原本
达到了贝叶斯最优错误率. 换言之, 若指数损失函数最小化, 则分类错误率也将最小化; 这说明指数损失函数是分类任务原本 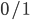 损失函数的一直的(Consistent)替代函数. 由于这个替代函数有更好的数学性质, 例如它是连续可微函数, 因此我们用它代替 损失函数作为优化目标. 在AdaBoost算法中, 第一个基分类器
损失函数的一直的(Consistent)替代函数. 由于这个替代函数有更好的数学性质, 例如它是连续可微函数, 因此我们用它代替 损失函数作为优化目标. 在AdaBoost算法中, 第一个基分类器 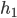 是通过直接将基学习算法用于初始数据分布而得; 此后迭代地生成
是通过直接将基学习算法用于初始数据分布而得; 此后迭代地生成 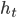 和
和 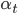 当基分类器 基于分布
当基分类器 基于分布 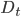 产生后, 改基分类器的权重 应使得
产生后, 改基分类器的权重 应使得 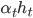 最小化指数损失函数:
最小化指数损失函数:
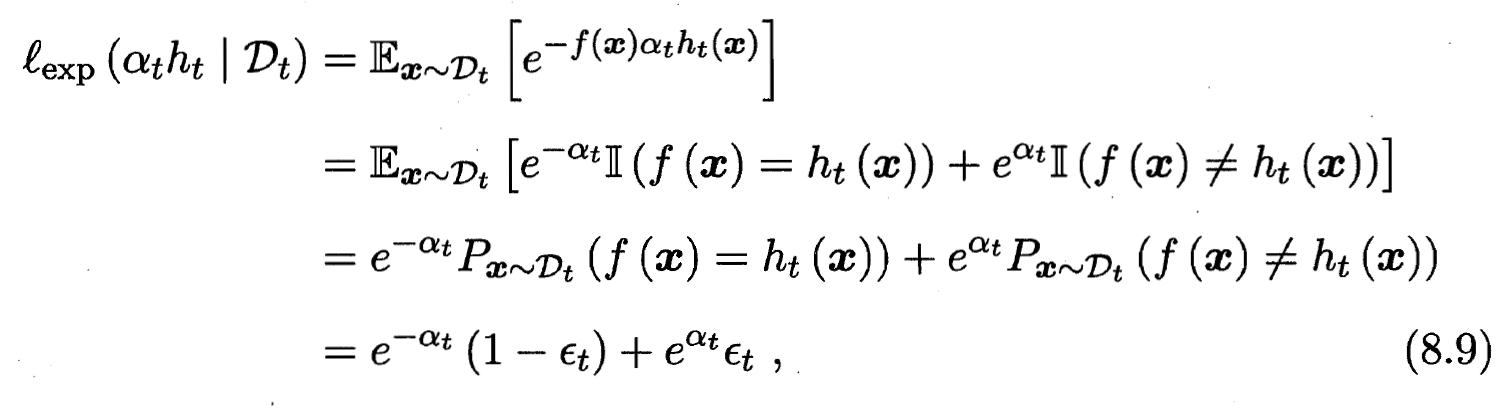
- 其中
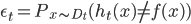 . 考虑指数损失函数的导数:
. 考虑指数损失函数的导数:
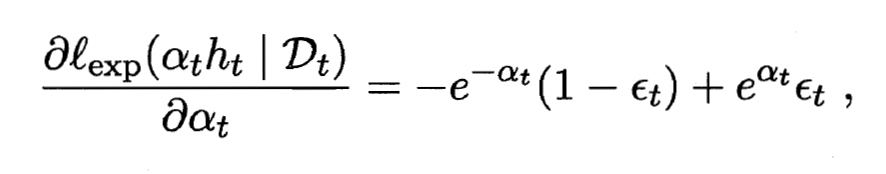
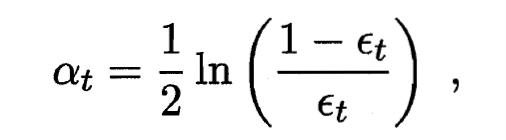
- 这恰恰是分类器权重更新公式. AdaBoost算法在获得
 之后样本分布将进行调整, 使下一轮的及学习器 能纠正
之后样本分布将进行调整, 使下一轮的及学习器 能纠正  的一些错误. 理想的 能纠正 的全部错误, 即最小化:
的一些错误. 理想的 能纠正 的全部错误, 即最小化:
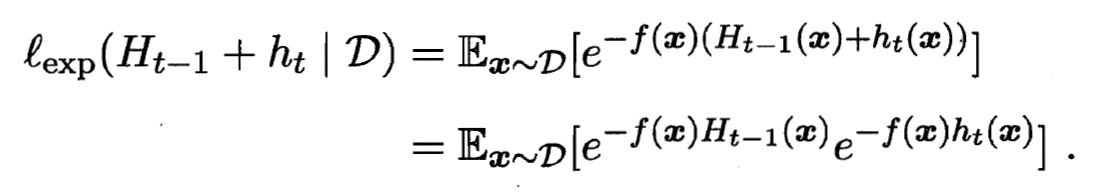
- 注意到
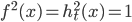 , 则上式可使用
, 则上式可使用 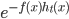 的泰勒展开式近似为:
的泰勒展开式近似为:
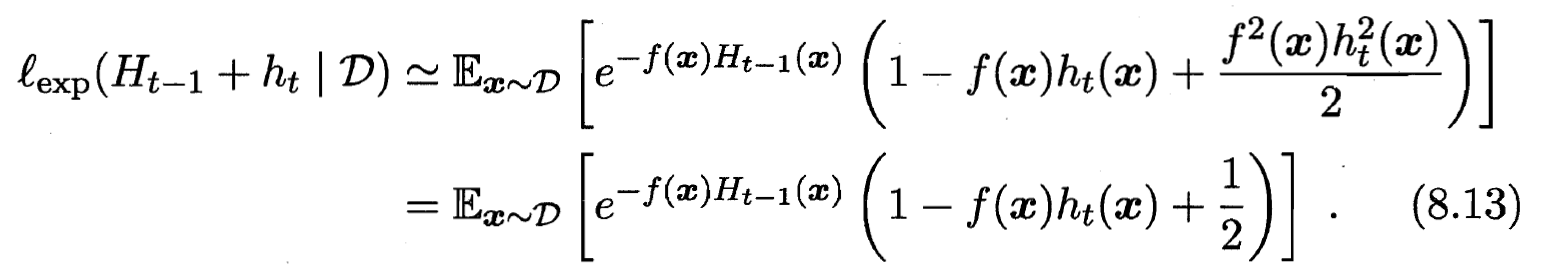
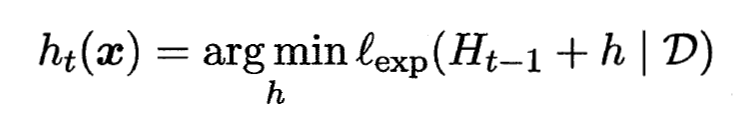
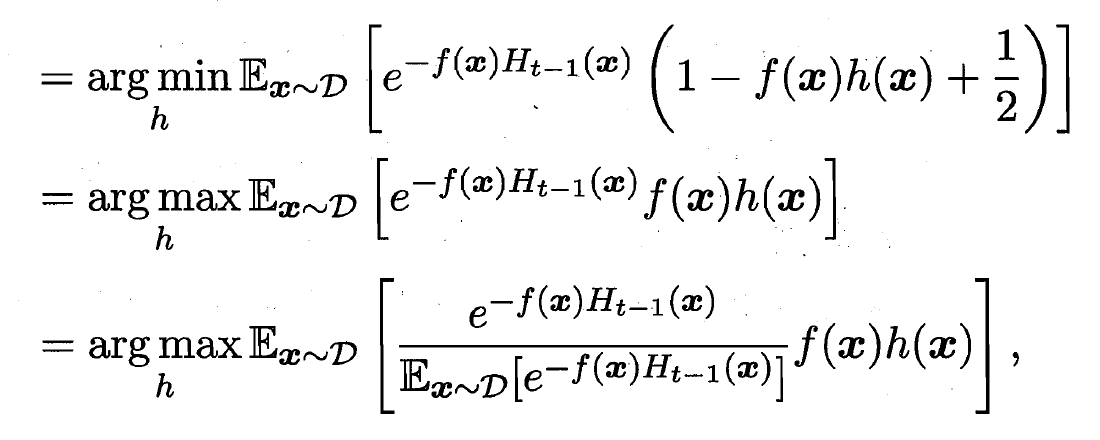
- 注意到
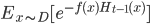 是一个常数. 令 表示一个分布:
是一个常数. 令 表示一个分布:
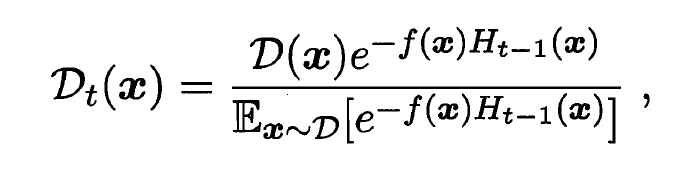
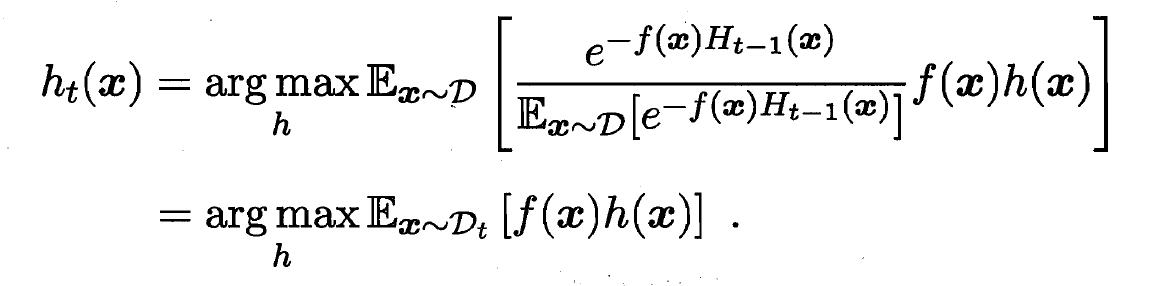
- 由
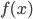 ,
, 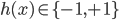 , 有:
, 有:
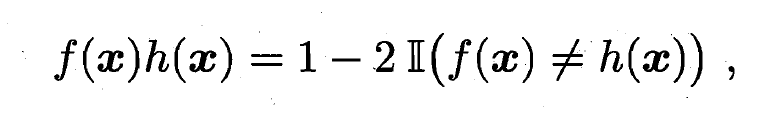
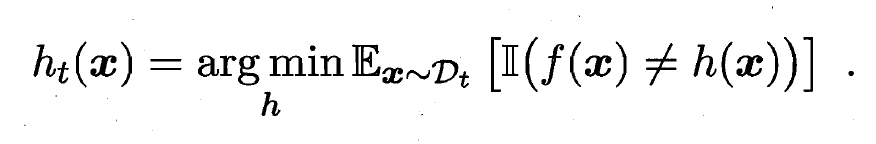
- 由此可见, 理想的 将在分布 下最小化分类误差. 因此弱分类器将基于分布 来训练, 且针对 的分类误差应小于 0.5. 在一定程度上类似'残差逼近'的思想. 考虑到 和
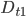 的关系, 有:
的关系, 有:
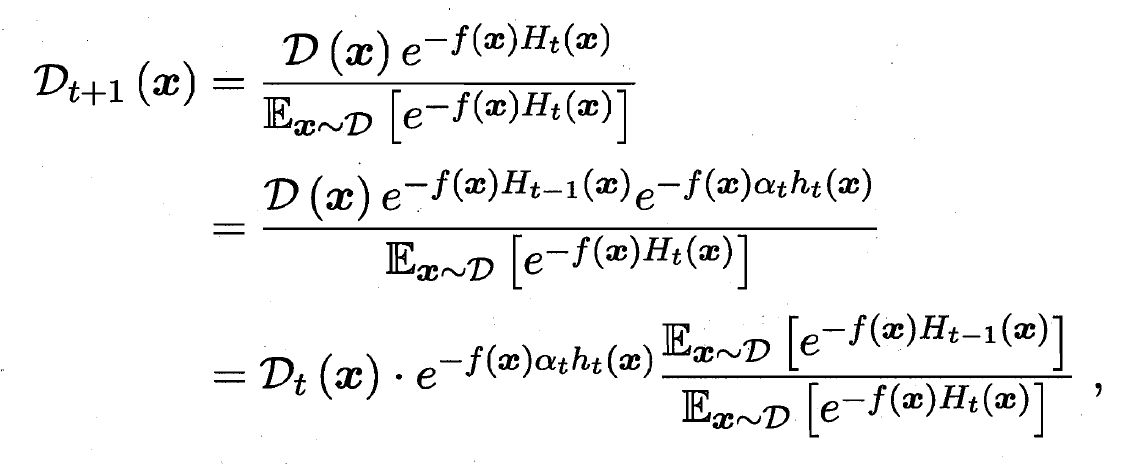
- 这恰是样本分布更新公式, 于是, 我们从基于加性模型迭代式优化指数损失函数的角度推导出了AdaBoost算法. Boosting算法要求基学习器能对特定的数据分布进行学习, 这可通过'重赋权法'(re-weighting)实施, 即在训练过程的每一轮中, 根据样本分布为每个训练样本重新赋予一个权重. 对无法接受带权重样本的基学习算法, 即可通过'重采样法'(re-sampling)来处理, 即在每一轮学习中, 根据样本分布对训练集重新进行采样, 在用重采样而得到的样本集对基学习器进行训练.
写在后面
- 今天, 我们学习了集成学习中的Boosting; 明天, 我们将继续学习集成学习中的Bagging与随机森林.
Related
Be First to Comment