Press "Enter" to skip to content
写在前面
- 昨天, 我们学习了集成学习中的Boosting; 今天, 我们继续学习集成学习中的Bagging与随机森林.
Bagging
- Bagging是并行式集成学习方法最著名的代表, 从名字即可看出, 它直接基于我们上节介绍过的自助采样法(Boostrap Sampling). 给定包含
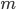 个样本的数据集, 我们先随机取出一个样本放入采样集中, 再把改样本放回初始数据集, 使得下次采样时该样本仍有可能被选中, 这样, 经过 次随机采样操作, 我们得到含 个样本的采样集, 初始训练集只能怪有的样本在采样集里多次出现, 有的则从未出现. 照这样, 我们可采样出
个样本的数据集, 我们先随机取出一个样本放入采样集中, 再把改样本放回初始数据集, 使得下次采样时该样本仍有可能被选中, 这样, 经过 次随机采样操作, 我们得到含 个样本的采样集, 初始训练集只能怪有的样本在采样集里多次出现, 有的则从未出现. 照这样, 我们可采样出 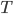 个含 个训练样本的采样集, 然后基于每个采样集训练处一个基学习器,再讲这些基学习器进行结合. 这就是Bagging的基本流程. 在对预测输出进行结合时, Bagging通常对分类任务使用简单投票法, 对回归任务使用简单平均法. 若分类预测时出现两个类收到同样票数的情形, 则最简单的做法是随机选择一个, 也可进一步考虑学习器投票的置信度来确定最终胜者. 如下图:
个含 个训练样本的采样集, 然后基于每个采样集训练处一个基学习器,再讲这些基学习器进行结合. 这就是Bagging的基本流程. 在对预测输出进行结合时, Bagging通常对分类任务使用简单投票法, 对回归任务使用简单平均法. 若分类预测时出现两个类收到同样票数的情形, 则最简单的做法是随机选择一个, 也可进一步考虑学习器投票的置信度来确定最终胜者. 如下图:

- 随机森林(Random Forest, 简称RF)是Bagging的一个扩展变体. RF在以决策树为基学习器构建Bagging集成的基础上, 进一步在决策树的训练过程中引入了随机属性选择. 具体来说, 传统决策树在选择划分属性时是在当前节点的属性集合(假定有
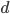 个属性)中选择一个最优属性; 而在RF中, 对基决策树的每个节点, 先从该节点的属性集合中随机选择一个包含
个属性)中选择一个最优属性; 而在RF中, 对基决策树的每个节点, 先从该节点的属性集合中随机选择一个包含 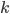 个属性的子集, 然后再从这个子集中选择一个最优属性用于划分. 这里的参数 控制了随机性的引入程度: 若令
个属性的子集, 然后再从这个子集中选择一个最优属性用于划分. 这里的参数 控制了随机性的引入程度: 若令 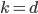 , 则基决策树的构建与传统决策树相同; 若令
, 则基决策树的构建与传统决策树相同; 若令 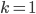 , 则是随机选择一个属性用于划分; 一般情况下, 推荐值
, 则是随机选择一个属性用于划分; 一般情况下, 推荐值 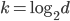 . 如下图:
. 如下图:
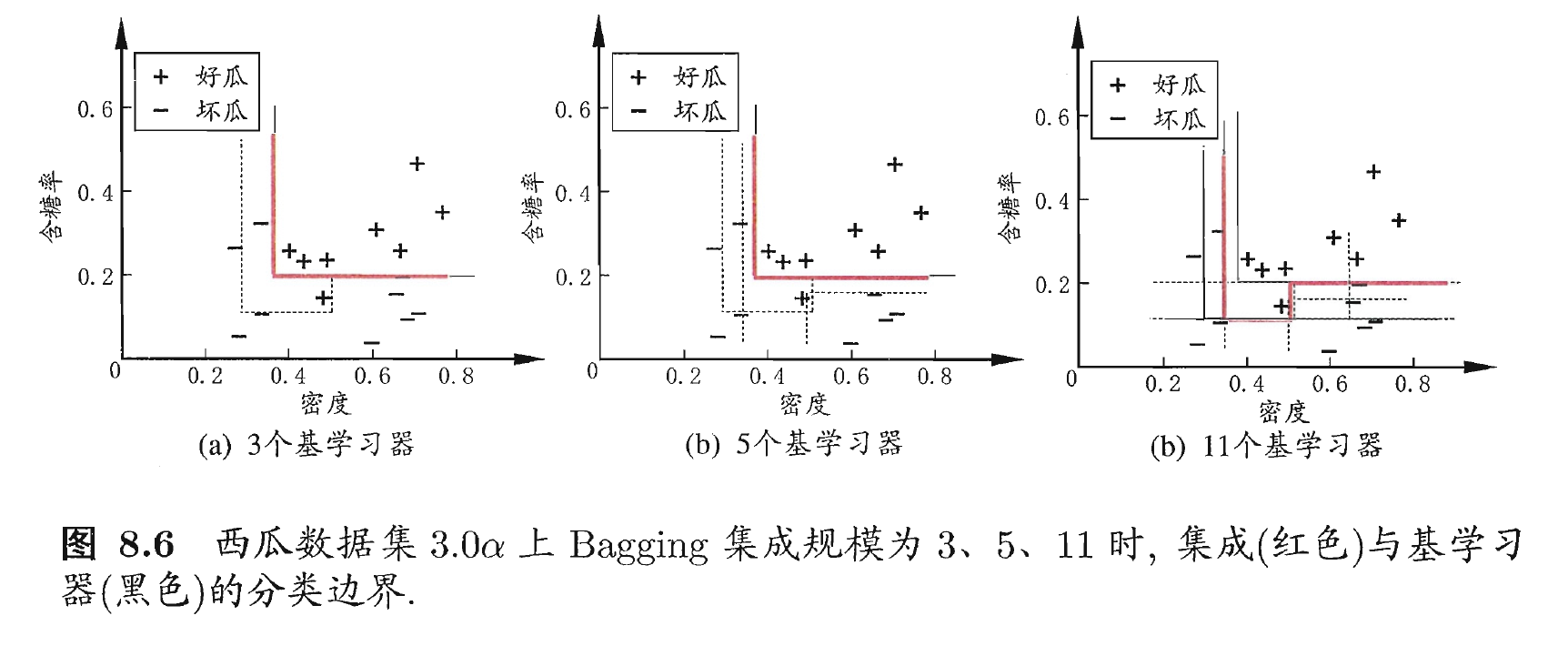
写在后面
- 今天, 我们学习了集成学习中的Bagging与随机森林; 明天, 我们将继续学习集成学习中的结合策略.
Related
Be First to Comment