Press "Enter" to skip to content
写在前面
- 昨天, 我们系统的学习了贝叶斯分类器中的半朴素贝叶斯分类器; 今天, 我们继续学习贝叶斯分类器中的贝叶斯网.
贝叶斯网
- 贝叶斯网(Bayesian Network)亦称'信念网'(Belief Network), 它借助有向无环图(Directed Acyclic Graph, 简称DAG)来刻画属性之间的依赖关系, 并使用条件概率表(Conditional Probability Table, 简称CPT)来描述属性的联合概率分布.
- 具体来说, 一个贝叶斯网
 由结构
由结构  和参数
和参数 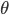 两部分构成, 即
两部分构成, 即  . 网络结构 是一个有向无环图, 其每个节点对应一个属性, 若两个属性有直接依赖关系, 则他们由一条边连接起来; 参数 定量描述这种依赖关系, 假设属性
. 网络结构 是一个有向无环图, 其每个节点对应一个属性, 若两个属性有直接依赖关系, 则他们由一条边连接起来; 参数 定量描述这种依赖关系, 假设属性 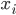 在 中的父结点集为
在 中的父结点集为  , 则 包含了每个属性的条件概率表
, 则 包含了每个属性的条件概率表  .
.
结构
- 贝叶斯网结构有效地表达了属性建的条件独立性. 给定父节点集, 贝叶斯网假设每个属性与它的非后裔属性独立, 于是
 将属性
将属性  的联合概率分布定义为:
的联合概率分布定义为:


- 显然,
 和
和  在给定
在给定 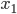 的取值时独立, 和
的取值时独立, 和  在给定的
在给定的  取值时独立, 分别简记为
取值时独立, 分别简记为  和
和  . 下图显示出贝叶斯网中三个变量之间的典型依赖关系:
. 下图显示出贝叶斯网中三个变量之间的典型依赖关系:

- 在'同父'(Common Parent)结构中, 给定父节点 的取值, 则 与 条件独立. 在'顺序'结构中, 给定
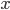 的值, 则
的值, 则 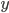 与
与  条件独立. V型结构(V-Structure)亦称'冲撞'结构, 给定子结点 的取值, 与 必不独立; 奇妙的是, 若 的取值完全未知, 则V型结构下 与 却是相互独立的.
条件独立. V型结构(V-Structure)亦称'冲撞'结构, 给定子结点 的取值, 与 必不独立; 奇妙的是, 若 的取值完全未知, 则V型结构下 与 却是相互独立的.
- 事实上, 一个变量取值的确定与否, 能对另两个变量间的独立性发生影响, 这个现象并非V型结构所特有.
学习
- 若网络结构已知, 即属性间的依赖关系已知, 则贝叶斯网的学习过程相对简单, 只需通过对训练样本'计数', 估计出每个节点的条件概率表即可. 但在现实应用中我们往往并不知晓网络结构, 于是, 贝叶斯网学习的首要任务就是根据训练数据集来找出结构最'恰当'的贝叶斯网. '评分搜索'是求解这一问题的常用办法. 具体来说, 我们先定义一个评分函数(Score Function), 以此来评估贝叶斯网与训练数据的契合程度, 然后基于这个评分函数来寻找结构最优的贝叶斯网. 显然, 评分函数引入了关于我们希望获得什么样的贝叶斯网的归纳偏好.
- 常用评分函数通常基于信息论准则, 此类准则将学习问题看做一个数据压缩任务, 学习的目标是找到一个能以最短编码长度和使用该模型描述数据所需的字节长度. 对贝叶斯网学习而言, 模型就是一个贝叶斯网, 同事, 每个贝叶斯网描述了一个在训练数据上的概率分布, 自由一套编码机制能使那些经常出现的样本有更短的编码. 于是, 我们应选择那个综合编码长度(包括描述网络和编码数据)最短的贝叶斯网, 这就是'最小描述长度'(Minimal Description Length, 简称MDL)准则.
推断
- 贝叶斯网训练好之后就能用来回答'查询'(Query), 即通过一些属性变量的观测值来推测其他属性变量的取值. 通过已知变量观测值来推测待查询变量的过程称为'推断'(Inference), 已知变量观测值为'证据'(Evidence).
- 最理想的是直接根据贝叶斯网定义的联合概率分布来精确计算后验概率, 不幸的是, 这样的'精确推断'已被证明是NP难的; 换言之, 当网络结点较多, 链接稠密时, 难以进行精确推断, 此时需借助'近似推断', 通过降低精度要求, 在有限时间内求得近似解. 在现实应用中, 贝叶斯网的近似推断常使用吉布斯采样(Gibbs Sampling)来完成, 这事一种随机采样方法
写在后面
- 今天, 我们学习了贝叶斯分类器中的贝叶斯网; 明天, 我们将继续学习贝叶斯分类器中的EM算法.
Related
Be First to Comment