Press "Enter" to skip to content
写在前面
- 前几天, 我们系统的学习了SVM相关的一些知识, 今天我们将开启一个新的章节贝叶斯分类器, 我们先来看看第一个小节中的内容, 贝叶斯决策论.
贝叶斯决策论
- 贝叶斯决策轮(Bayesian Decision Theory)是概率框架下实施决策的基本方法. 对分类任务来说, 在所有行管概率都已知的理想情形下, 贝叶斯决策轮考虑如何基于这些概率和误判损失来选择最优的类别标记. 我们以多分类任务为例来解释其基本原理.
- 假设有
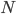 种可能的类别标记, 即
种可能的类别标记, 即 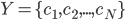 ,
, 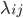 是一个将真实标记为
是一个将真实标记为 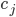 的样本误分类为
的样本误分类为 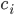 所产生的损失. 基于后验概率
所产生的损失. 基于后验概率 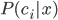 可获得将样本
可获得将样本 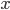 分类为 所产生的期望损失(Expected Loss), 即在样本 上的'条件风险'(Conditional Risk):
分类为 所产生的期望损失(Expected Loss), 即在样本 上的'条件风险'(Conditional Risk):
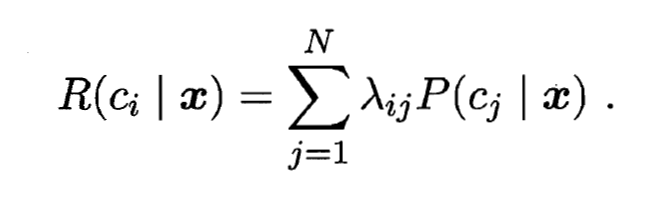
- 我们的任务是寻找一个判定准则
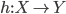 以最小化总体风险:
以最小化总体风险:
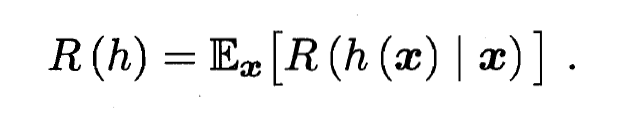
- 显然, 对每个样本 , 若
 能最小化条件风险
能最小化条件风险 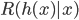 , 则总体风险
, 则总体风险 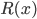 也将被最小化. 这就产生了贝叶斯判定准则(Bayes Decision Rule): 为最小化总体风险, 只需在每个样本上选择那个能使条件风险
也将被最小化. 这就产生了贝叶斯判定准则(Bayes Decision Rule): 为最小化总体风险, 只需在每个样本上选择那个能使条件风险 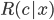 最小的类别标记, 即:
最小的类别标记, 即:
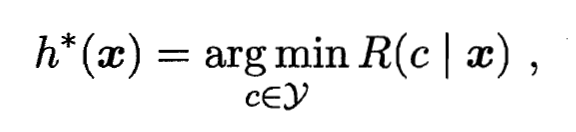
- 此时,
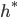 称为贝叶斯最优分类器(Bayes Optimal Classifier), 与之对应的总体风险
称为贝叶斯最优分类器(Bayes Optimal Classifier), 与之对应的总体风险 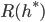 称为贝叶斯风险(Bayes Risk).
称为贝叶斯风险(Bayes Risk). 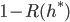 反映了分类器所能达到的最好性能, 即通过机器学习所能产生的模型精度的理论上线. 具体来说, 若目标是最小化分类错误率, 则误判损失 可写为:
反映了分类器所能达到的最好性能, 即通过机器学习所能产生的模型精度的理论上线. 具体来说, 若目标是最小化分类错误率, 则误判损失 可写为:
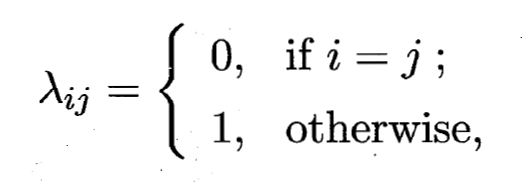
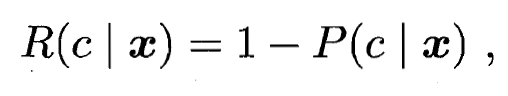
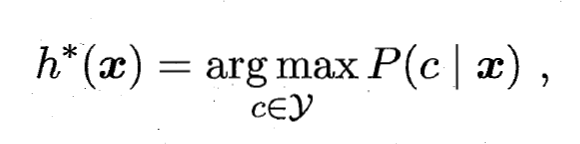
- 即对每个样本 ,选择能使后延概率
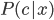 最大的类别标记. 不难看出, 欲使用贝叶斯判定准则来最小化决策风险, 首先要获得后验概率 . 然而, 在现实任务中这通常难以直接获得. 从这个角度来看, 机器学习所要实现的是基于有限的训练样本集尽可能准确地估计出后验概率 . 大体来说, 主要有两种策略: 给定 , 可通过直接建模 来预测
最大的类别标记. 不难看出, 欲使用贝叶斯判定准则来最小化决策风险, 首先要获得后验概率 . 然而, 在现实任务中这通常难以直接获得. 从这个角度来看, 机器学习所要实现的是基于有限的训练样本集尽可能准确地估计出后验概率 . 大体来说, 主要有两种策略: 给定 , 可通过直接建模 来预测  , 这样得到的是'判别式模型'(Discriminative Models); 也可先对联合概率分布
, 这样得到的是'判别式模型'(Discriminative Models); 也可先对联合概率分布 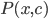 建模, 然后再由此获得 , 这样得到的是'生成式模型'(Generative Models). 显然, 前面介绍的决策树, BP神经网络, 支持向量机等, 都可归入判别式模型的范畴. 对生成式模型来说, 必然考虑:
建模, 然后再由此获得 , 这样得到的是'生成式模型'(Generative Models). 显然, 前面介绍的决策树, BP神经网络, 支持向量机等, 都可归入判别式模型的范畴. 对生成式模型来说, 必然考虑:
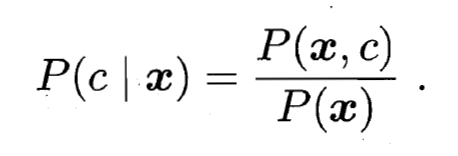
- 基于贝叶斯定理, 可写为:
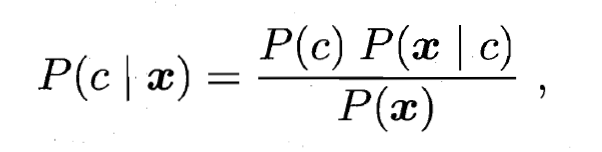
- 其中,
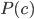 是类'先验'(Prior)概率;
是类'先验'(Prior)概率; 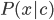 是样本 相对于类标记 的类条件概率(Class-Conditional Probability), 或称为'似然'(Likelihood);
是样本 相对于类标记 的类条件概率(Class-Conditional Probability), 或称为'似然'(Likelihood); 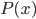 是用于归一化的'证据'(Evidence)因子. 对给定样本 , 证据因子 与类标记无关, 因此估计 的问题就转化为如何基于训练数据
是用于归一化的'证据'(Evidence)因子. 对给定样本 , 证据因子 与类标记无关, 因此估计 的问题就转化为如何基于训练数据 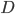 来估计先验 和似然 . 类先验概率 表达了样本空间中各类样本所占的比例, 根据大数定律, 当训练集包含充足的独立同分布样本时, 可通过各类样本出现的频率来进行估计.
来估计先验 和似然 . 类先验概率 表达了样本空间中各类样本所占的比例, 根据大数定律, 当训练集包含充足的独立同分布样本时, 可通过各类样本出现的频率来进行估计.
- 对类条件概率
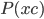 来说, 由于它涉及关于 所有属性的联合概率, 直接根据样本出现的频率来估计将会遇到严重的困难. 例如, 假设样本的
来说, 由于它涉及关于 所有属性的联合概率, 直接根据样本出现的频率来估计将会遇到严重的困难. 例如, 假设样本的 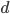 个属性都是二值的, 则样本空间将有
个属性都是二值的, 则样本空间将有 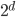 种可能的取值, 在现实应用中, 这个值往往远大于训练样本数
种可能的取值, 在现实应用中, 这个值往往远大于训练样本数 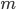 , 也就是说, 很多样本取值在训练集中根本没有出现, 直接使用频率来估计 显然不可行, 因为'未被观测到'与'出现频率为零'通常是不同的.
, 也就是说, 很多样本取值在训练集中根本没有出现, 直接使用频率来估计 显然不可行, 因为'未被观测到'与'出现频率为零'通常是不同的.
写在后面
- 今天, 我们学习了贝叶斯分类器中的贝叶斯决策论; 明天, 我们将继续学习贝叶斯分类器中的极大似然估计.
Related
Be First to Comment