写在前面
在这个章节中, 我们将讨论Accuracy(准确率), Precision(精确率), Recall(召回率), F-Score(F分数) 这几个对模型效果评价的指标. 在这章中, 我们将只讨论二元分类的情况.
混淆矩阵
| Positive | Negative | |
|---|---|---|
| True | TP(True Positive) | FN(True Negative) |
| False | FP(False Positive) | TN(False Negative) |
- 我们必须先了解混淆矩阵, 才能继续后面的计算.
- TP(True Positive): 真正, 将正类预测为正类数, 准确预测出正类.
- TN(True Negative): 真负, 将负类预测为负类数, 准确预测出负类.
- FP(False Positive): 假正, 将负类预测为正类数, 错误将负类预测成正类.
- FN(False Negative): 假负, 将正类数预测为负类数, 错误将正类预测成负类.
对应测试集的真实值与预测值, 转换成如下表格:
| Predict | ||||
|---|---|---|---|---|
| R | True | False | Sum | |
| e | True | TP | FN | RealTrue |
| a | False | FP | TN | RealFalse |
| l | Sum | PredictTrue | PredictFalse | TestSet |
备注: 在此表格中, RealTrue表示所有真实值为真的数据计数, RealFalse表示所有真实值为假的数据计数, PredictTrue表示所有预测值为真的数据计数, PredictFalse表示所有预测值为假的技术, TestSet表示此测试集的数据计数.
Accuracy
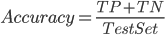
Accuracy, 准确率, 顾名思义, 在所有预测的结果中, 预测准确的概率.
ErrorRate
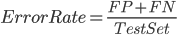
Error rate, 错误率, 与准确率相反, 在所有预测结果中, 被错误预测的概率.
Sensitivity
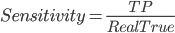
Sensitivity, 敏感性, 有多少真值被准确预测到了.
Specitivity
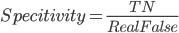
Specitivity, 特异性, 有多少假值被准确预测到了.
Precision
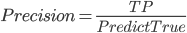
Precision, 精确率, 在所有预测为真的结果中, 有多少真值被准确预测到了.
Recall
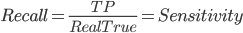
Recall, 召回率, 用来度量有多少正确的结果被正确归类, 计算方式跟敏感度一样.
F1-Score
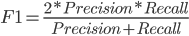
F1-Score是精确率和召回率的调和均值.
Fn-Score
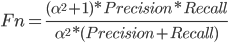
Fn是精确率和召回率的加权调和均值, 当  时就是F1, 当Fn-Score与F1得分较高时, 说明此模型的适配性较高.
时就是F1, 当Fn-Score与F1得分较高时, 说明此模型的适配性较高.
Samples
- 对于垃圾邮件的预测, 我们希望是准确的, 可是我们又不想遗漏那些重要的邮件, 这个时候, 精确率对我们来说就很重要, 而召回率只要不是太大就不会对我们造成太大的困扰.
- 对于癌症患者的预测, 我们希望宁可错杀一千, 不可放过一个, 因为, 对于误诊为癌症的健康人, 无非就是回来多做一些复查, 在多项检查为正常后, 则可视为正常; 否则将癌症病人视为正常人, 可能会耽误治疗, 会造成很严重的后果. 这个时候, 我们会很重视召回率, 召回率可能会很高, 而精确率可能会略低.
写在最后
整体来说, 这些值都很好理解, 只是用的时候, 要如何根据实际情况来做调优, 例如说对于垃圾邮件和癌症病人的预测, 针对不同的情况来对  值做优化. 在实际应用中, 这些问题是值得深究的.
值做优化. 在实际应用中, 这些问题是值得深究的.
Be First to Comment