Press "Enter" to skip to content
写在前面
- 昨天, 我们学习了聚类中的距离计算; 今天, 我们将继续学习聚类中的原型聚类.
原型聚类
- 原型聚类亦称'基于原型的聚类'(prototype-based clustering), 此类算法假设聚类结构能通过一组原型刻画, 在显示聚类任务中极为常用. 通常情形下, 算法先对原型进行初始化, 然后对原型进行迭代更新求解. 采用不同的原型表示, 不同的求解方式, 将产生不同的算法.
k均值算法
- 给定样本集
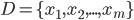 , 'k均值'(k-means)算法针对聚类所得簇划分
, 'k均值'(k-means)算法针对聚类所得簇划分 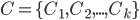 最小化平方误差
最小化平方误差
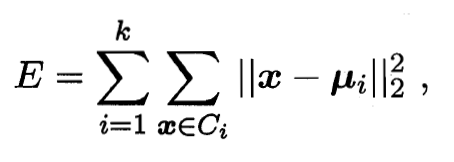
- 其中
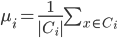 ,
, 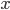 是簇
是簇 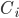 的均值向量. 直观来看, E值越小则簇内样本相似度越高.
的均值向量. 直观来看, E值越小则簇内样本相似度越高.

学习向量量化
- 与k均值算法相似, '学习向量量化'(Learning Vector Quantization, 简称LVQ)也是视图找到一组原型向量来刻画聚类结构, 但与一般聚类算法不同的是, LVQ假设数据样本带有类别标记, 学习过程利用样本的这些监督信息来辅助聚类.
- 给定样本集
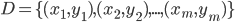 , 每个样本
, 每个样本 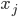 是由n个属性描述的特征向量
是由n个属性描述的特征向量 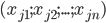 ,
, 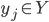 是样本 的类别标记, LVQ的目标是学得一组n维原型向量
是样本 的类别标记, LVQ的目标是学得一组n维原型向量 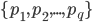 , 每个原型向量代表一个聚类簇, 簇标记
, 每个原型向量代表一个聚类簇, 簇标记 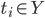 .
.

高斯混合聚类
- 与k均值, LVQ用原型向量来刻画聚类结构不同, 高斯混合(Mixture-of-Gaussian)聚类采用概率模型来表达聚类原型.

写在后面
- 今天, 我们学习了聚类中的原型聚类; 明天, 我们将继续学习聚类中的密度聚类.
Related
Be First to Comment