写在前面
在这个章节里面, 我们将会更深入的研究决策树.
贪心算法
贪心算法|贪婪算法: 在对问题求解时, 总是做出在当前看来是最好的选择. 也就是说, 不从整体最优上加以考虑, 他所做出的是在某种意义上的局部最优解. 而我们现在所研究的决策树, 也是一种贪心算法.
奥卡姆剃刀
奥卡姆剃刀: 切勿浪费较多东西, 去做'用较少的东西, 同样可以做好的事情'. 简单点说, 便是: be simple.
可线性分离的数据
如下图, 假设我们的朋友Tom喜欢冲浪, 但是冲浪需要满足两个条件, 要有风, 要有太阳, 图中坐标中横轴表示风的大小, 纵轴表示太阳的大小, 他不会在天气不够晴朗的时候去冲浪, 也不会在风力较弱的时候去冲浪, 他只会在有风并且天晴的时候去冲浪. 图中'x'表示不会冲浪, 'o'表示会冲浪. 那么, 结合下图, 这些数据是线性可分的吗?
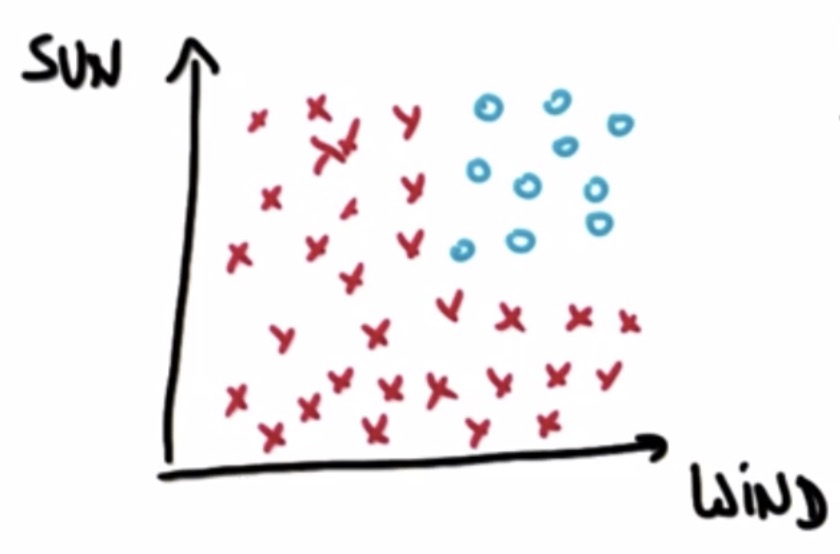
显然, 这些数据是不能被线性分割的, 因为我们无法在这个空间中找到可以分割这些数据的直线.
多元线性问题
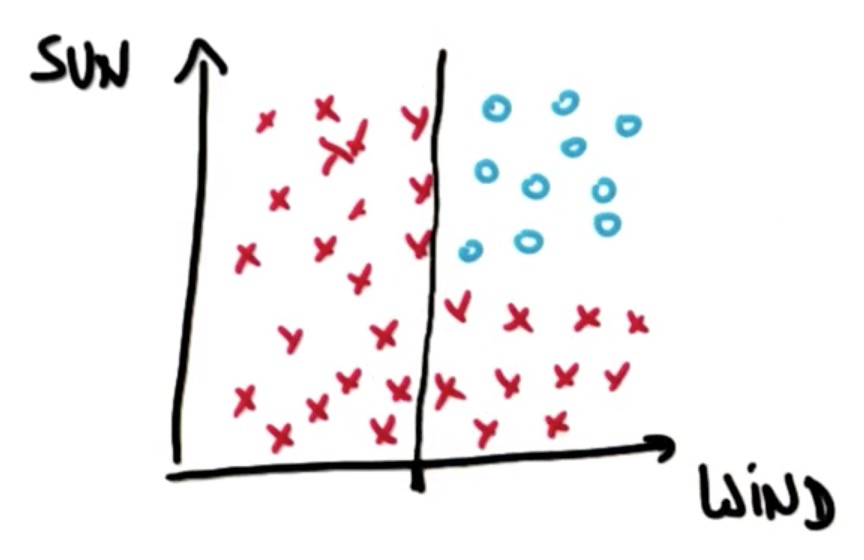
对于这个问题的研究, 我们可以先问, 有没有风, 我们可以在横轴上设定一个阈值, 这个阈值设定了一个决策面, 当数据的横轴值在这个点右边时, 则判断为有风, 左边为无风. 可以发现, 两个结果中, 已经有一个代表了最终的分类结果, 那就是左边那一部分, 当没有风的时候, Tom不会去冲浪. 然而在有风的情况下, 我们则需要考虑天气是否晴朗的问题.

这里, 我们可以在纵轴上也设定一个阈值, 这个阈值决定了是否天晴.
如果天气不晴朗, 那就会得到'x', 也就是不能冲浪.
如果天气晴朗, 会得到'o', 可以冲浪.
最终, 我们得到以下决策树:
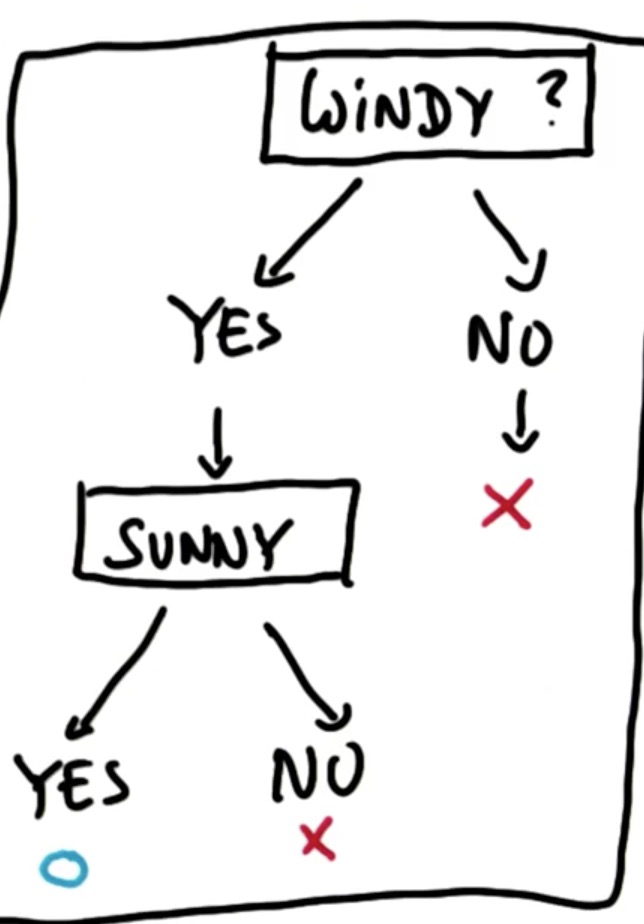
代码实现
关于代码实现与sklearn的使用, 请参照另外一篇博文DecisionTree Classifier.
在使用DecisionTreeClassifier()训练数据时, 可以使用sklearn.metrics中的accuracy_score()函数来对数据准确性进行评分.
Entropy(熵)
定义: 熵是一系列样本中的不纯度的测量值.
关于熵的定义与计算方法, 请参照另外一篇博文Entropy.
在使用决策树对数据分割时, 要尽可能减少杂质, 熵的值越小越好.
Information Gain(信息增益)
关于信息增益的定义与计算方法, 请参照另外一篇博文Information Gain.
在决策树中, 算法会最大化信息增益.
决策树的优缺点
优点: 易于使用, 结构清晰, 能够以图形化方式很好的剖析数据, 结果清晰容易理解.
缺点: 容易overfit(过拟合), 需要谨慎调参.
写在最后
在这章内容中, 我们重点讨论了决策树是如何对数据进行分割, 以及熵与信息增益的计算过程, 以及它的优缺点所在.
在下一章中, 我们将重点讨论决策树的可表达性与ID3算法.
Be First to Comment