写在前面
- 昨天, 我们学习了, SVM中的核函数; 今天, 我们将接下去学习SVM中的软间隔与正则化.
软间隔与正则化
- 在前面的讨论中, 我们一直假定训练样本在样本空间或特征空间中是线性可分的, 即存在一个超平面能将不同类的样本完全划分开. 然而, 在现实任务中往往很难确定合适的核函数使得训练样本在特征空间中线性可分; 退一步说, 即便恰好找到了某个核函数使训练集在特征空间中线性可分, 也很难断定这个貌似线性可分的结果不是由于过拟合所造成的.
- 缓解该问题的一个办法是允许支持向量机在一些样本上出错. 为此, 要引入'软间隔'(Soft Margin)的概念, 如下图:
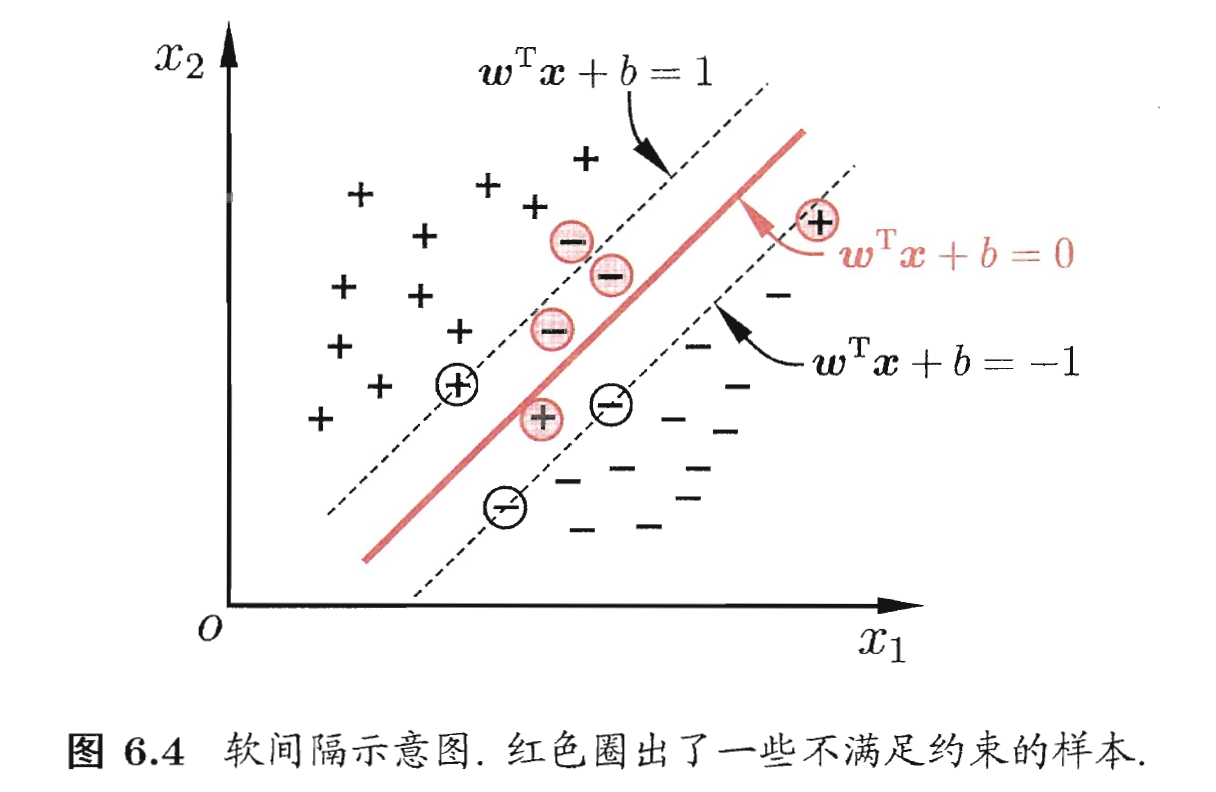
- 具体来说, 前面介绍的支持向量机形式是要求所有样本均满足约束, 即所有样本都必须划分正确, 这称为'硬间隔'(Hard Margin), 而软间隔则是允许某些样本不满足约束:
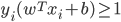
- 当然, 在最大化间隔的同事, 不满足约束的样本应尽可能少. 于是优化目标可写为:
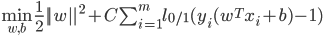
- 其中
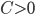 是一个常数,
是一个常数, 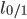 是 '
是 ' 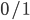 损失函数':
损失函数':
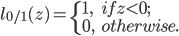
- 然而, 非凸, 非连续, 数学性质不太好, 不易直接求解. 于是, 人们通常用其他一些函数来代替 , 称为'替代损失'(Surrogate Loss). 替代损失函数一般具有较好的数学性质, 如他们通常是凸的连续函数且是 的上界, 三种常用的替代函数:
1.hinge损失: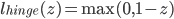
2.指数损失(Exponential Loss):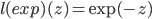
3.对率损失(Logistic Loss):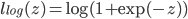
- 若采用hinge损失, 则有:
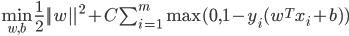
- 引入'松弛变量'(Slack Variables)
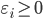 , 则有:
, 则有:
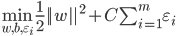

- 如上图, 这就是常用的'软间隔支持向量机'.
- 显然, 每个样本都有一个对应的松弛变量, 用以表征改样本不满足约束的程度. 这仍是一个二次规划问题. 于是, 通过拉格朗日乘子发可得到上式的拉格朗日函数:

- 其中
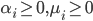 是拉格朗日乘子. 令
是拉格朗日乘子. 令 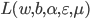 对
对 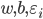 的偏导为零可得:
的偏导为零可得:
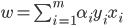
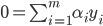
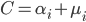
- 即可得到对偶问题:
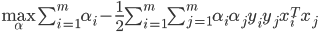
s.t.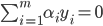
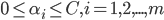
- 对比两者可看出, 两者的唯一差别就在于对偶变量的约束不同: 前者是
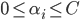 , 后者是
, 后者是 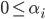 . 于是在引入核函数后能得到同样的支持向量式. 对软间隔支持向量机, KKT条件要求:
. 于是在引入核函数后能得到同样的支持向量式. 对软间隔支持向量机, KKT条件要求:

- 于是, 对任意训练样本
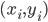 , 总有
, 总有 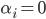 或
或 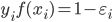 . 若 , 则该样本不会对
. 若 , 则该样本不会对 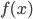 有任何影响; 若
有任何影响; 若 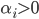 , 则必有 , 即改样本是支持向量: 若
, 则必有 , 即改样本是支持向量: 若 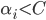 , 则
, 则 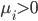 , 进而有
, 进而有 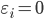 , 即该样本落在恰在最大间隔边界上; 若
, 即该样本落在恰在最大间隔边界上; 若 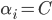 , 则有
, 则有 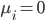 , 此时若
, 此时若 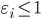 则该样本落在最大间隔内部, 若
则该样本落在最大间隔内部, 若 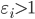 则该样本被错误分类. 由此可看出, 软间隔支持向量机的最总模型仅与支持向量有关, 即通过采用hinge损失函数仍保持了洗属性.
则该样本被错误分类. 由此可看出, 软间隔支持向量机的最总模型仅与支持向量有关, 即通过采用hinge损失函数仍保持了洗属性. - 那么能否使用其他的替代损失函数呢? 可以发现, 如果使用对率损失函数
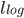 来替代上面的 损失函数, 则几乎就得到了对率回归模型. 实际上, 支持向量机与对率回归的优化目标镶金, 通常情形下它们的性能也相当. 对率回归的优势主要在于其输出具有自然的概率意义, 即在给出预测标记的同时也给出了概率, 而支持向量机的输出不具有概率意义, 欲得到概率输出需进行特殊处理, 此外, 对率回归能直接用于对分类任务, 支持向量机为此则需进行推广. 另一方面, 可以看出hinge损失有一块'平坦'的零区域, 这使得支持向量机的解具有洗属性, 而对率损失是光滑的单调递减函数, 不能导出类似支持向量的概念, 因此对率回归的解依赖于更多的训练样本, 其预测开销更大.
来替代上面的 损失函数, 则几乎就得到了对率回归模型. 实际上, 支持向量机与对率回归的优化目标镶金, 通常情形下它们的性能也相当. 对率回归的优势主要在于其输出具有自然的概率意义, 即在给出预测标记的同时也给出了概率, 而支持向量机的输出不具有概率意义, 欲得到概率输出需进行特殊处理, 此外, 对率回归能直接用于对分类任务, 支持向量机为此则需进行推广. 另一方面, 可以看出hinge损失有一块'平坦'的零区域, 这使得支持向量机的解具有洗属性, 而对率损失是光滑的单调递减函数, 不能导出类似支持向量的概念, 因此对率回归的解依赖于更多的训练样本, 其预测开销更大. - 我们还可以把 损失函数替换成别的替代损失函数以得到其他学习模型, 这些模型的性质与所用的替代函数直接相关, 但他们具有一个共性: 优化目标中的第一项用来描述划分超平面的'间隔'大小, 另一项
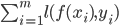 用来表述训练集上的误差, 可写为更一般的形式:
用来表述训练集上的误差, 可写为更一般的形式:
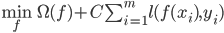
- 其中
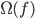 称为'结构风险'(Structural Risk), 用于描述模型
称为'结构风险'(Structural Risk), 用于描述模型 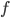 的某些性质; 第二项 称为'经验风险'(Empirical Risk), 用于描述模型与训练数据的契合程度;
的某些性质; 第二项 称为'经验风险'(Empirical Risk), 用于描述模型与训练数据的契合程度; 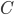 用于对二者进行折中. 从经验风险最小化的角度来看, 表述了我们希望获得具有何种性质的模型(例如希望获得复杂度较小的模型), 这位引入领域知识和用于意图提供了途径; 另一方面, 该信息有助于削减假设空间, 从而降低了最小化训练误差的过拟合风险. 从这个角度来说, 上式被称为'正则化'(Regularization)问题, 称为正则化项, 则称为正则化常数.
用于对二者进行折中. 从经验风险最小化的角度来看, 表述了我们希望获得具有何种性质的模型(例如希望获得复杂度较小的模型), 这位引入领域知识和用于意图提供了途径; 另一方面, 该信息有助于削减假设空间, 从而降低了最小化训练误差的过拟合风险. 从这个角度来说, 上式被称为'正则化'(Regularization)问题, 称为正则化项, 则称为正则化常数. 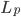 范数(Norm)是常用的正则化项, 其中
范数(Norm)是常用的正则化项, 其中 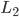 范数
范数 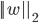 倾向于
倾向于 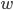 的分量取值尽量均衡, 即非零分量个数尽量稠密, 而
的分量取值尽量均衡, 即非零分量个数尽量稠密, 而 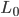 范数
范数 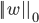 和
和 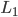 范数
范数 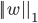 则倾向于 的分量尽量稀疏, 即非零分量个数尽量少.
则倾向于 的分量尽量稀疏, 即非零分量个数尽量少.
s.t. 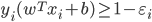
写在后面
- 今天, 我们学习了SVM中的软间隔与正则化; 明天, 我们将继续学习SVM中的支持向量回归.
Be First to Comment