写在前面
- 在上一个章节中, 我们学习了线性模型. 在这篇文章中, 我们将会继续学习决策树相关的一些知识.
基本流程
- 决策树(Decision Tree)是一种常见的机器学习方法. 以二分类任务为例, 我们希望从给定训练数据集学的一个模型用以对新示例进行分类, 这个把样本分类的任务, 可以看做对'当前样本属于正类吗?'这个问题的'决策'或'判定'过程. 顾名思义, 决策树是基于树结构来进行决策的, 这恰是人类在面临决策问题时一种很自然的处理机制.
- 一般的, 一棵决策树, 包含一个根节点, 若干个内部节点和若干个叶节点; 叶节点对应于决策结果, 其他每个节点则对应于一个属性测试; 每个节点包含的样本集合根据属性测试的结果被划分到子节点中; 根节点包含样本全集. 从根节点到每个叶节点的路径对应了一个判定测试序列. 决策树学习的目的是为了产生一颗泛化能力强, 即处理未见示例能力强的决策树, 其基本流程遵循简单且直观的'分而治之'(Divide-And-Conquer)策略, 如下图:

- 显然, 决策树的生成是一个递归过程. 在决策树基本算法中, 有三种情形会导致递归返回:
1.当前节点包含的样本全属于同一类别, 无需划分.
2.当前属性集为空, 伙食所有样本在所有属性上取值相同, 无法划分.
3.当前节点包含的样本集合为空, 不能划分.
- 在第2种情形下, 我们把当前节点标记为叶节点, 并将其类别设定为该节点所包含样本最多的类别; 在第3种情形下, 同样吧当前节点标记为叶节点, 但将其类别设定为其父节点所含样本最多的类别. 注意这两种情形的处理实质不同: 情形2是在利用当前节点的后验分布, 而情形3则是吧父节点的样本分布作为当前节点的先验分布.
划分选择
- 一般而言, 随着划分过程不断进行, 我们希望决策树的分支节点点所包含的样本尽可能属于同一类别, 即节点的'纯度'(Purity)越来越高.
- 信息增益(Information Entropy)是度量样本集合纯度最常用的一种指标. 假设当前样本集合
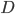 中第
中第 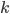 类样本所占的比例为
类样本所占的比例为 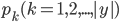 , 则 的信息熵定义为:
, 则 的信息熵定义为:
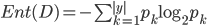
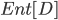 的值越小, 则 的纯度越高.
的值越小, 则 的纯度越高. - 假定离散属性
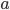 有
有 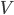 个可能的取值
个可能的取值 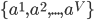 , 若使用 来对样本集 进行划分, 则会产生 个分值节点, 其中第
, 若使用 来对样本集 进行划分, 则会产生 个分值节点, 其中第 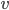 个分值结点包含了 中所有在属性 上取值为
个分值结点包含了 中所有在属性 上取值为 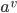 的样本, 记为
的样本, 记为 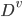 . 我们可以根据上式计算出 的信息熵, 再考虑到不同的分值节点所包含的样本数不同, 给分值节点赋予权重
. 我们可以根据上式计算出 的信息熵, 再考虑到不同的分值节点所包含的样本数不同, 给分值节点赋予权重 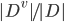 , 即样本数越多的分值结点的影响越大, 于是可以计算出用属性 对样本集 进行划分所获得的 '信息增益'(Information Gain):
, 即样本数越多的分值结点的影响越大, 于是可以计算出用属性 对样本集 进行划分所获得的 '信息增益'(Information Gain):
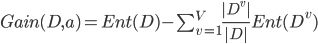
- 如果这里有问题的话, 可以参考下<information gain>.
- 一般而言, 信息增益越大, 则意味着使用属性 来进行划分所得的'纯度提升'越大. 因此, 我们可以用信息增益来进行决策树的划分属性选择. 著名的
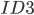 决策树学习算法就是以信息增益为准则来选择划分属性. 即:
决策树学习算法就是以信息增益为准则来选择划分属性. 即:
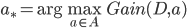
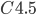 决策树算法, 不直接使用信息增益, 而是使用'增益率'(Gain Ratio)来选择最优划分属性. 增益率定义为:
决策树算法, 不直接使用信息增益, 而是使用'增益率'(Gain Ratio)来选择最优划分属性. 增益率定义为:
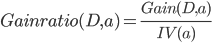
其中:
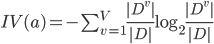
称为属性 的'固有值'(Intrinsic Value). 属性 的可能取数目越多(即 越大), 则 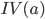 的值通常会越大.
的值通常会越大.- 需注意的是, 增益率准则对可取值数目较少的属性有所偏好, 因此, 算法并不是直接选择增益率最大的候选划分属性, 二十使用了一个启发式: 先从候选划分属性中找出信息增益率高于平均水平的属性, 再从中选择增益率最高的.
- CART决策树, 使用'基尼指数'(Gini Index)来选择划分属性. 数据集 的纯度可用基尼值来度量:
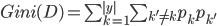
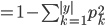
- 直观来说,
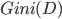 反映了从数据集 中随机抽取两个样本, 其类别标记不一致的概率. 因此 越小, 数据集 的纯度越高.
反映了从数据集 中随机抽取两个样本, 其类别标记不一致的概率. 因此 越小, 数据集 的纯度越高. - 属性 的基尼指数定义为:
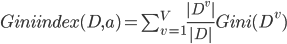
- 于是, 我们在候选属性集合
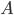 中, 选择那个使得划分后基尼指数最小的属性作为最优划分属性, 即
中, 选择那个使得划分后基尼指数最小的属性作为最优划分属性, 即 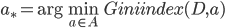 .
.
写在后面
- 在这篇文章中, 对决策树相关的基本流程与划分选择. 相比之下, 可能会比较好理解, 希望大家在读完这篇文章了之后, 能对信息熵与信息增益也会有个大致的了解.
- 明天, 我们将会继续学习剪枝处理, 连续与缺失值这两个小节中的内容.
Be First to Comment