写在前面
- 昨天, 我们学习了集成学习中的Bagging与随机森林; 今天, 我们将继续学习集成学习中的结合策略.
结合策略
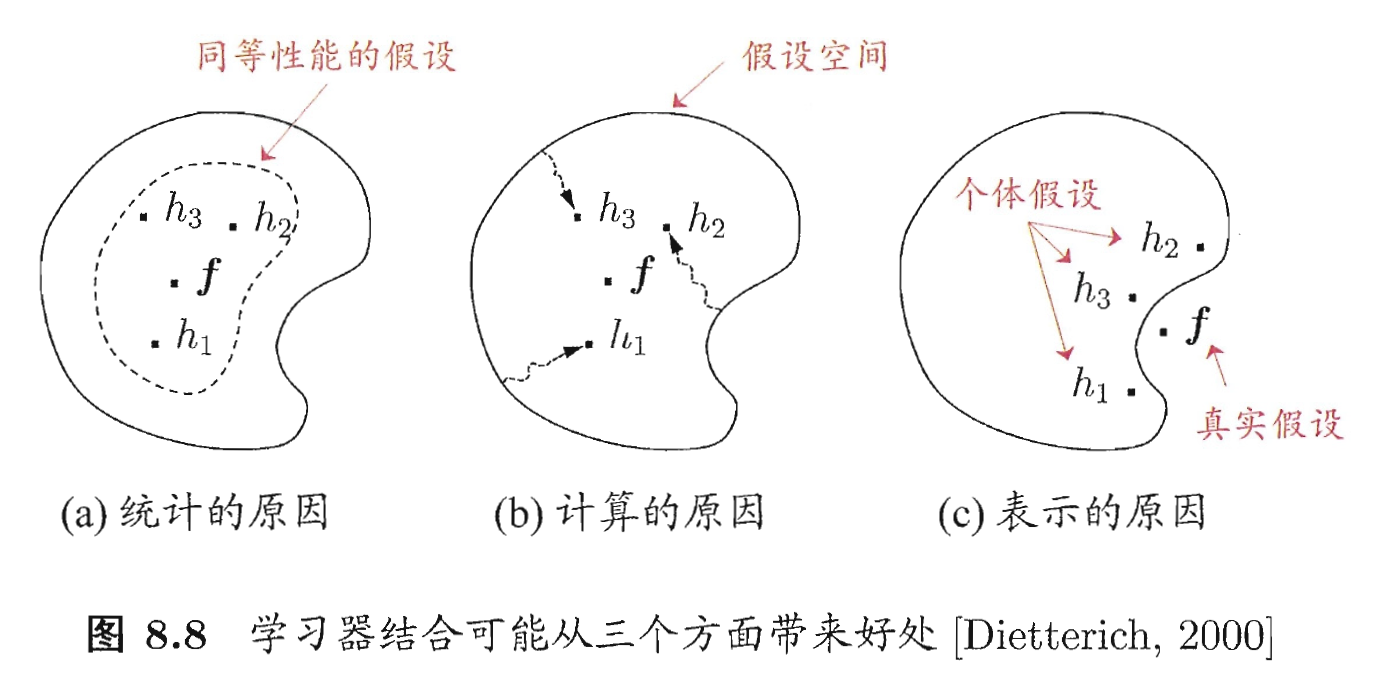
- 学习器结合可能会从三个方面带来好处: 首先, 从统计的方面来看, 由于学习任务的假设空间往往很大, 可能有多个假设在训练集上达到同等性能, 此时若使用单学习器可能因误选而导致泛化性能不佳, 结合多个学习器则会减小这一风险; 第二, 从计算的方面来看, 学习算法往往会陷入局部极小点所对应的泛化性能可能很糟糕, 而通过多次运行之后进行结合, 可降低陷入糟糕局部绩效点的风险; 第三, 从表示的方面来看, 某些学习任务的真实假设可能不在当前学习算法所考虑的假设空间中, 此时若使用单学习期则肯定无效, 而通过结合多个学习器, 由于相应的假设空间有所扩大, 有可能学得更好的近似, 如下图:
- 对数值型输出
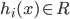 , 最常见的结合策略是使用平均法(Averaging).
, 最常见的结合策略是使用平均法(Averaging). - 简单平均法(Simple Averaging):
假定集成包含  个基学习器
个基学习器 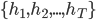 , 其中
, 其中 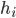 在示例
在示例 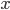 上的输出为
上的输出为 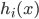 . 本节介绍几种对 进行结合的常见策略.
. 本节介绍几种对 进行结合的常见策略.
平均法
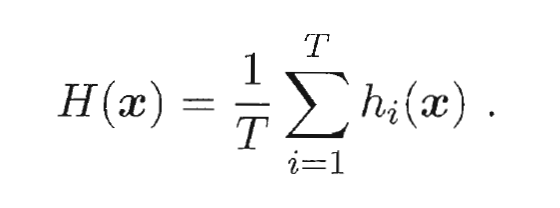
- 加权平均法(Weighted Averaging):
- 对分类任务来说, 学习器 将从类别标记集合
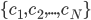 中预测出一个标记, 最常见的结合策略是使用投票法(Voting). 为便于讨论, 我们将 在样本 上的预测输出表示为一个
中预测出一个标记, 最常见的结合策略是使用投票法(Voting). 为便于讨论, 我们将 在样本 上的预测输出表示为一个 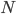 维向量
维向量 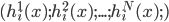 , 其中
, 其中 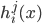 是 在类别标记
是 在类别标记 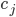 上的输出.
上的输出. - 绝对多数投票法(Majority Voting):
- 相对多数投票法(Plurality Voting):
- 加权投票法(Weighted Voting):
- 当训练数据很多时, 一种更为强大的结合策略是使用'学习法', 即通过另一个学习器来进行结合. Stacking是学习法的典型代表. 这里我们把个体学习器称为初级学习器, 用于结合的学习器称为次级学习器或原学习器(Meta-Learner). Stacking先从初始数据训练集训练处初级学习器, 然后'生成'一个新数据集用于训练次级学习器. 在这个新数据集中, 初级学习器的输出被当做样例输入特征, 而初始样本的标记被当做样例标记. Stacking的算法描述如下图, 这里我们假定初级学习器使用不同学习算法产生, 即初级集成是异质的:
- 今天, 我们学习集成学习中的结合策略; 明天, 我们将继续学习集成学习中的多样性.
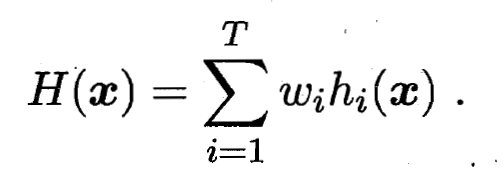
其中, 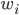 是个体学习器 的权重, 通常要求
是个体学习器 的权重, 通常要求 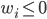 ,
, 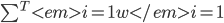 .
.
投票法
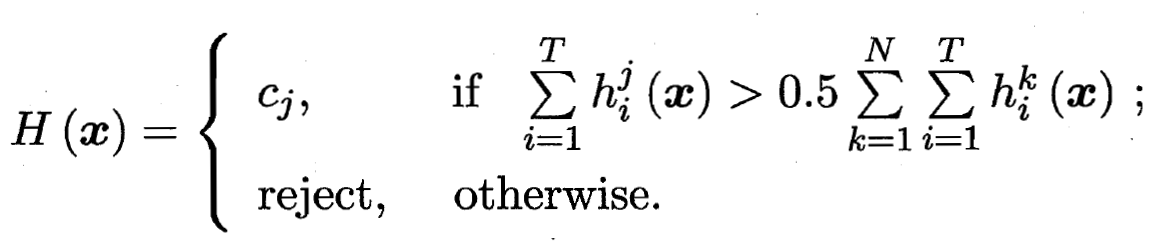
即若某标记得票过半数, 则预测为该标记; 否则拒绝预测.
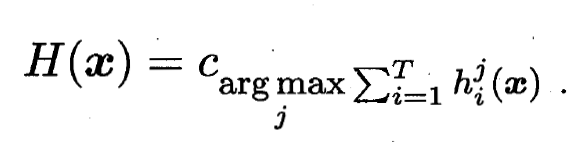
即预测为得票最多的标记, 若同时有多个标记获得最高票, 则从中随机选取一个.
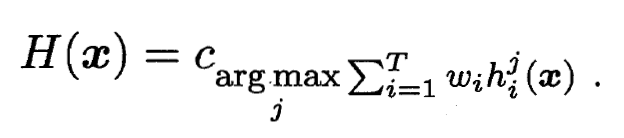
与甲醛平均法类似, 是 的权重, 通常 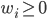 ,
,
学习法

Be First to Comment