Press "Enter" to skip to content
写在前面
- 昨天, 我们学习了集成学习中的多样性; 今天, 我们将继续学习聚类中的聚类任务.
聚类任务
- 在'无监督学习'(unsupervised learning)中, 训练样本的标记信息是未知的, 目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律, 为进一步的数据分析提供基础. 此类学习任务中研究最多, 应用最广的是'聚类'(Clustering).
- 聚类试图将数据集中的样本划分为若干个通常是不相交的子集, 每个子集称为一个'簇'(Cluster). 通过这样的划分, 每个簇有可能对应于一些潜在的概念(类别). 需要说明的是, 这些概念对聚类算法而言事先是未知的, 聚类过程仅能自动形成簇结构, 簇所对应的概念语义需由使用者来把握和命名.
- 形式化地说, 假定样本集
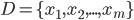 包含
包含 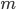 个无标记样本, 每个样本
个无标记样本, 每个样本 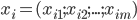 是一个
是一个 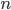 维特征向量, 则聚类算法将样本集
维特征向量, 则聚类算法将样本集 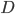 划分为
划分为 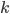 个不相交的簇
个不相交的簇 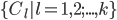 , 其中
, 其中 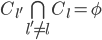 且
且 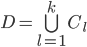 . 相应地, 我们用
. 相应地, 我们用 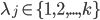 表示样本
表示样本 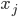 的'簇标记'(Cluster Label), 即
的'簇标记'(Cluster Label), 即 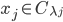 . 于是, 聚类的结果可用包含 个元素的簇标记向量
. 于是, 聚类的结果可用包含 个元素的簇标记向量 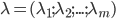 表示.
表示.
- 聚类既能作为一个单独过程, 用于找寻数据内在的分布结构, 也可作为分类等其他学习任务的前驱过程. 例如, 在一些商业应用中需对新用户的类型进行判别, 但定义'用户类型'对商家来说却可能不太容易, 此时往往可先对用户数据进行聚类, 根据聚类结果将每个簇定义为一个类, 然后再基于这些类训练分类模型, 用于判别新用户的类型.
- 基于不同的学习策略, 人们设计出多种类型的聚类算法.
写在后面
- 今天, 我们学习了聚类中的聚类任务; 明天, 我们将继续学习聚类中的性能度量.
Related
Be First to Comment