写在前面
- 昨天, 我们学习了贝叶斯分类器中的贝叶斯网; 今天, 我们将继续学习贝叶斯分类器中的EM算法.
EM算法
- 在前面的讨论中, 我们一直假设训练样本所有属性变量的值都已被观测到, 即训练样本是'完整'的. 但在现实应用中往往会遇到'不完整'的训练样本. 未观测变量的学名是'隐变量'(Latent Variable). 令
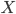 表示已观测变量集,
表示已观测变量集, 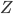 表示隐变量集,
表示隐变量集, 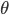 表示模型参数. 若欲对 做极大似然估计, 则应最大化对数似然:
表示模型参数. 若欲对 做极大似然估计, 则应最大化对数似然:
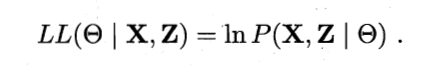
- 然而由于 是隐变量, 上式无法直接求解. 此时我们可以通过对 计算期望, 来最大化已观测数据的对数'边际似然'(Marginal Likelihood):
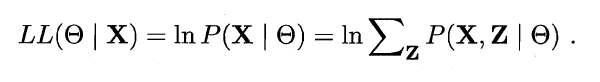
- EM(Expectation-Maximization)算法是常用的估计参数隐变量的利器, 他是一种迭代式的方法, 其基本想法是: 若参数 已知, 则可更具训练数据推断出最优隐变量 的值(E步); 反之, 若 的值已知, 则可方便地对参数 做极大似然估计(M步). 于是, 以
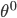 为起点, 可迭代执行以下步骤直至收敛
为起点, 可迭代执行以下步骤直至收敛 - 简单来说, EM算法使用两个步骤交替计算: 第一步是期望(E)步, 利用当前估计的参数值来计算对数似然的期望值; 第二部是最大化(M)步, 寻找能使E步产生的似然期望最大化的参数值. 然后得到的参数值重新被用于E步, ......直至收敛到局部最优解.
- 事实上, 隐变量估计问题也可以通过梯度下降等优化算法求解, 但由于求和的项数将随着隐变量的数目以指数级上升, 会给梯度计算带来麻烦; 而EM算法则可看做一种非梯度优化方法.

这就是EM算法的原型.
- 进一步, 若我们不是取 的期望, 而是基于 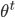 计算隐变量 (Z) 的概率分布
计算隐变量 (Z) 的概率分布 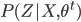 , 则EM算法的两个步骤是:
, 则EM算法的两个步骤是:

写在后面
- 今天, 我们学习了贝叶斯分类器中的EM算法; 明天, 我们将学习下一个章节, 集成学习中的个体与集成.
Be First to Comment